Machine Learning Notes: Attention Please
(Please refer to Wow It Fits! — Secondhand Machine Learning.)
This is my notes from [1706.03762] Attention Is All You Need and The Annotated Transformer and The Illustrated Transformer. This is an outline, I’m trying to keep it as simple as possible. You can import these layers and blocks from torch.nn, see Transformer Layers. And I will focus more on structure rather than code itself, because building this model on torch.nn is much simpler, see Language Modeling with nn.Transformer and torchtext.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output … the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
Recurrent neural networks (RNN), long short-term memory networks (LSTM) and gated RNNs have these shortages:
- They handle sequence word-by-word, which is hard to be parallelized.
- They are easy to forget a long sequence or mix previous content up with following content.
Attention mechanism has been used before, but Transformer is a pure attention architecture, that’s why “Attention is All You Need”.
§1 Self-Attention
$$\text{Attention}(Q, K, V) = \text{Softmax}(\frac{QK^\top}{\sqrt{d_{k}}})V \tag{1}$$where for a vector $\vec{z_i}$, $$\text{Softmax}(\vec{z_i}) = \frac{e^{\vec{z_i}}}{\sum_{i=0}^N e^{\vec{z_i}}} \tag{2}$$
For input $X$, to get $Q$ (Query), $K$ (Key), $V$ (Value), $$\begin{aligned} Q &= XW^Q \\ K &= XW^K \\ V &= XW^V \end{aligned} \tag{3}$$where $W^Q$, $W^K$, $W^V$ are training parameters.

§2 Multi-Head Attention
For the same input $X$, define different $W^Q_i$, $W^K_i$, $W^V_i$, we will get different $$\text{head}_i = \text{Attention} (QW^Q_i, KW^K_i, VW^V_i) \tag{4}$$$i =1, \cdots, h$. And concat them together, multiply with training parameter $W^0$, we will get $$\text{MultiHead} (Q, K, V) = \text{Concat}(\text{head}_1, \cdots, \text{head}_h) W^0 \tag{5}$$see this picture:
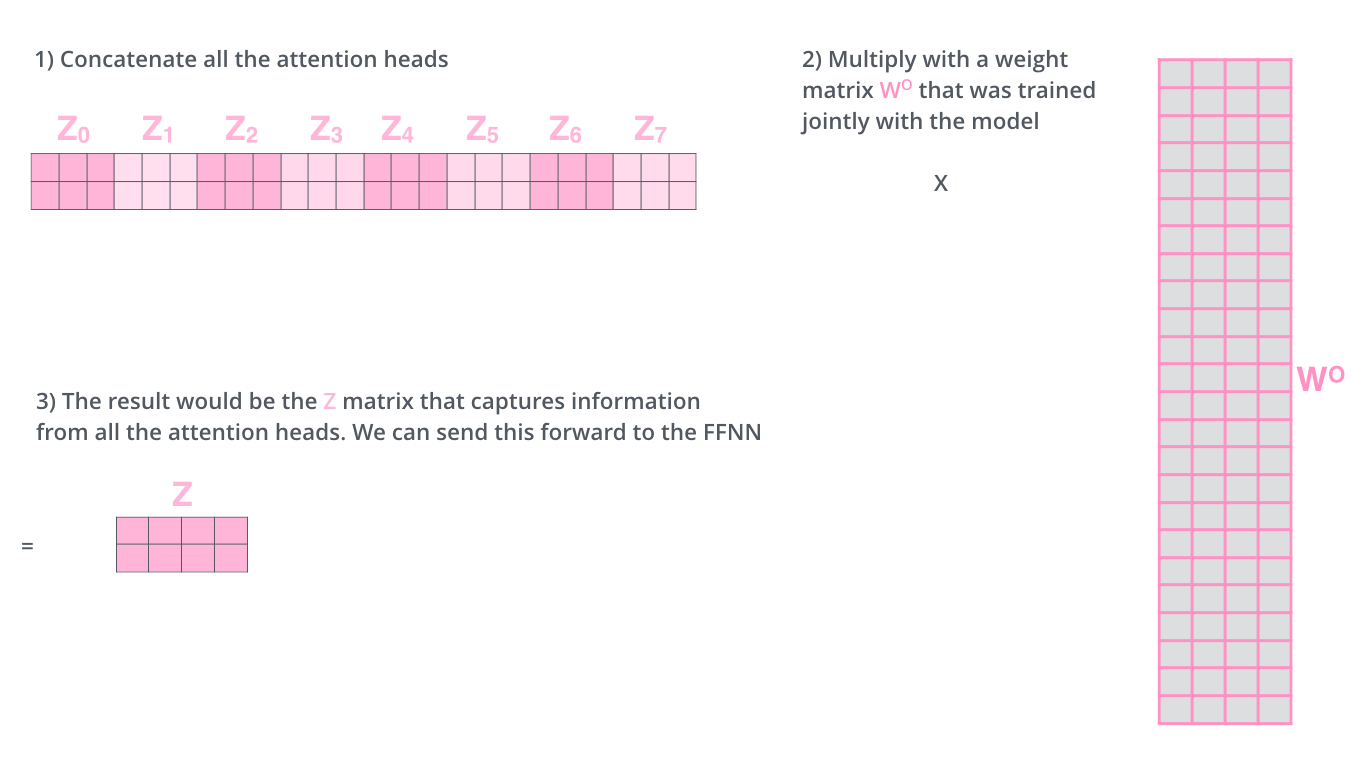
This is the explanation for Figure 2 in Attention Is All You Need.
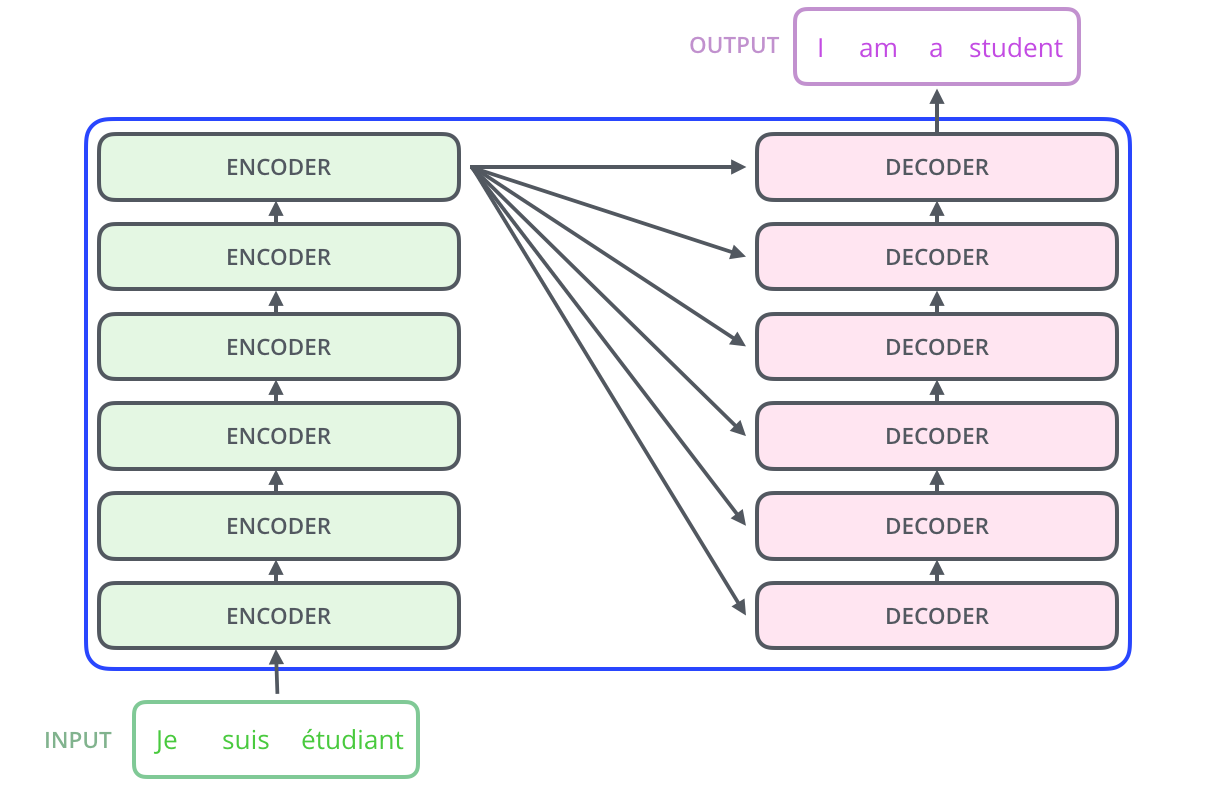
Attention is Encoder-Decoder structure:
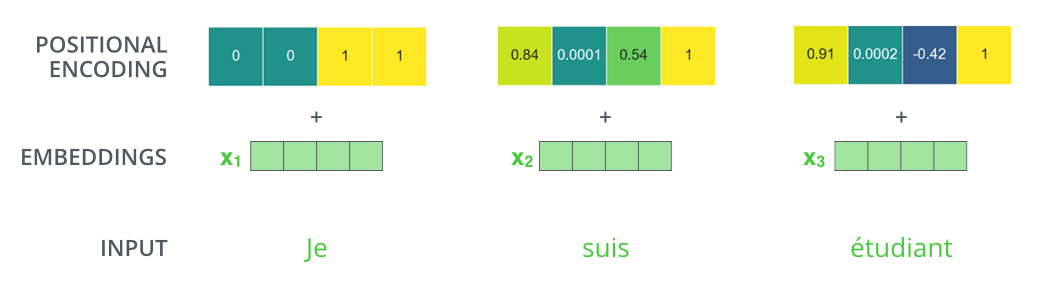
For a sentence with different $pos$ (up to $seq_{length}$, the maximum length of a sentence), and $j \in [0,d_{model}]$, where $d_{model}$ is the length of the representation vector (in this case $4$, see the picture below). The Positional Embedding is $$\begin{aligned} PE_{(pos, 2j)} &= \sin(\frac{pos}{ 10000^{2j/{d_{model}}}}) \\ PE_{(pos, 2j + 1)} &= \cos(\frac{pos}{10000^{2j/{d_{model}}}}) \end{aligned} \tag{6}$$Embedding is representation of discrete variables (in this case words or sub-words) by continuous (at least more continuous) vectors. Using $\sin$ and $\cos$ fits with Add & Norm layer where the inputs are normalized to $1$.
The Encoder will add the Embedding and Positional Embedding to get the input $X$, see picture below:
§3 Transformer
The structure of the full Transformer is:

§3.1 Add & Norm
- Add is similar to residual connections in ResNet. By introducing “shortcut” or “identity mapping”, the transformed input is added together with input.
- Norm is normalization layer.
§3.2 Feed Forward
- Composed of two Linear Layers and an activation function.
- The $1^\text{st}$ layer is $$\text{Linear}(X) = XW_1+b_1 \tag{7}$$
- Then is activation function ReLU$$\text{ReLU}(x)=\max{(0,x)} \tag{8}$$
- The $2^\text{nd}$ layer is $$\text{Linear}(X) = XW_2+b_2 \tag{9}$$
- So that we will get $$\text{FFN}(X)=(\max{(0,XW_1+b_1)})W_2+b_2 \tag{10}$$The output of Feed Forward will have the same dimension with input $X$ due to the selection of hyper-parameters.